
Last week I installed and ran an LLaMA 2 model on my wife Barbara’s Raspberry Pi 5. I conducted this small experiment to present a more concrete discussion of Wolfgang Ernst’s notion of technológos in an article I was writing – more on that below. My aim was to explain and problematize the relation between generative AI models and hardware by literally bringing them into one’s own hand. The premise was that if I could show in this article how to configure and run an LLM locally on a very small scale, using household equipment so to speak, then perhaps the infrastructural scope of generative AI models would become more graspable, and thus our relationship as individuals to this technological realm would be less, say, incommensurable. Then, since this exploratory process has been really rewarding, and I don’t want to just wait for the article to be published to talk about it, I’ve decided to write this brief note to share some semi-technical insights.
I had never worked with a Raspberry Pi before – my experience was limited to Arduino so far – and setting it up was thus a bit of a challenge. In my mind, probably due to my previous experience, Raspberry Pis were just microcontrollers, and not actual single-board computers that require peripherals to be operated; peripherals that I didn’t have, at least not in the recommended form – that is, a wired mouse and keyboard. Since I had configured the operating system to work over ssh – a wireless networking protocol – I was able to access the Raspberry Pi from my computer via WiFi using the terminal, where the bluetoothctl command allowed me to pair a Bluetooth mouse and keyboard with it. At first, however, my Bluetooth devices appeared in a list, among several others, by their alphanumeric Bluetooth addresses, and I wasn’t able to identify them properly. It was not until I borrowed my wife’s Magic Mouse, which was listed by its nickname, that I was able to gain proper control of the Raspberry Pi and begin the experiment.
Loading the LLaMA software and model was actually a straightforward process. Over the past year I had seen several reports of people running LLaMA and other LLMs families locally. But it was only when I found Gary Sims’s (GaryExplains) step-by-step guide to doing it on a Raspberry Pi that I really decided to give it a try. His guide provides all the terminal commands to install the necessary material on this device, and also recommends where to find good models and how to choose the most suitable one for your machine. In this sense, I was looking for a model in Spanish because the article I was writing was in that language; thus, I thought that the insights provided by the model would relate more naturally to this language context. The main platform for finding these models seems to be the Hugging Face. There, CliBrAIn offers several models in Spanish; not only based on Meta’s LLaMA, but also on Mamba, Mistral, etc. However, the lack of proper descriptions in these models made me look at Tim Jobbins’s (TheBloke) space at the Hugging Face, where he offers literally thousands of models based on different LLMs families, and actually in different languages. There I found what I was looking for. It is actually a LLaMA model originally created by CliBrAIn, but systematized and quantized by TheBloke. Accordingly, I chose a Q2 model with 7 billion of parameters. This choice was made on the recommendation of Gary Sim. In his guide, he stated that given the power of Raspberry Pis, it was safer to go with a, say, more modest model. After running the model, I found out that the difference in hardware between his machine, a Raspberry Pi 4, and mine, a Raspberry Pi 5, allowed me to go for something bigger – which I haven’t tried so far.
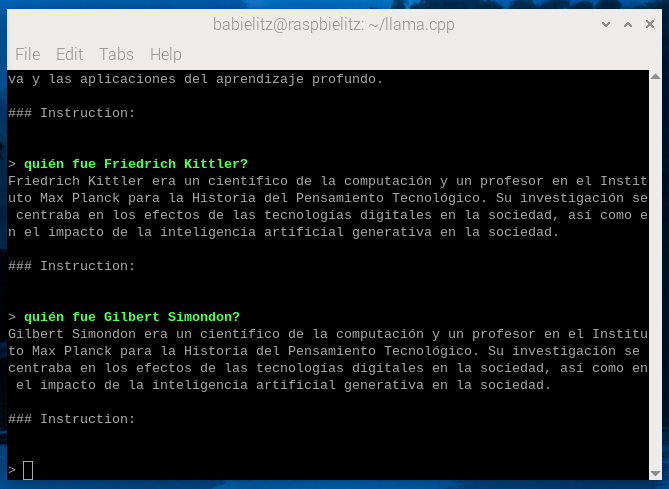
I set everything up to run the model in interactive mode; that is, as a chatbot. Everything ran very smoothly, and at a much faster pace than what Gary Sims described in his guide – that’s when I noticed the difference in hardware and performance. The grammatical structure of the answers I got was very impressive, and in the first round of prompts they were actually close to being correct – I asked about nineteenth century scientists and twentieth century scholars. As I progressed, however, the model became more and more inaccurate; a big liar or charlatan, if you want to add a sort of hermeneutic reading to this – see image below. Even when I kept asking about the same scientists and scholars in subsequent rounds – trying to replicate the context of the first round – the answers were more obviously wrong each time. I’m not sure what could be the reason for this behavior. At first I thought it was connected to the size of the model in terms of parameters and quantization, but maybe it is also related to the actual data base on which these models were trained – you can check out Meta’s original paper on LLaMA here to take a look at the sources they used. One of the most interesting or funny results I got was an answer to the question, in Spanish of course, “can a Raspberry Pi run a generative AI model?”, to which the model replied with a clear no.
Beyond the answers, however, my interest in this experiment was in the relation between the model and the hardware; in the micro-moments where the symbolic softness of the model – the symbols (characters), syntax, and programming instructions that make it up – gives way to the physical, electrical phenomena that take place in the different components of the Raspberry Pi’s architecture – main memory, processor, RAM, and so on. This is the techno-material topology that describes what Wolfgang Ernst calls technológos. As a media theoretical notion, it aims to describe and problematize the modes through which technology becomes an actual operative agent of media cultures – see Ernst’s Technológos in Being (2021) for more. In previous works, Ernst has argued that the role of technology in contemporary cultures is a fully active one, unfolding and deployed with important levels of autonomy; a capacity he has problematized more broadly through the notion of the agency of the machine – see Digital Memory and the Archive (2013). The principles of these historical decentrings – the agency of the machine and the technológos in being – are to be found in the operational crystallization of the mathematics at the base of the techno-scientific reality on which our contemporary cultures are built.
The case of generative AI, and of LLMs in particular, is problematic in this sense because, while it is a radical concretization of the rather theoretical notions outlined above, it is at the same time so vast and complex that it tends to be perceived as too abstract and ungraspable. The exercise of loading an LLM on a small single-board computer, and literally feeling with one’s own hand how the model operates and calculates the statistical probabilities that will lead to its answers – even if we cannot perceive these actual operations and calculations, but only the heat they produce – can be a first step towards commensurating the technological landscape in which we are embedded; towards understanding the meaning of the notion of technlógos and discerning our role in it.
A more detailed discussion of this Raspberry Pi experiment and of the notion of technológos in this context will be available when the article in question is published, hopefully later this year; an article and a publication that are actually devoted to discussing and contextualizing the work of Gilbert Simondon – but that is another story.
Berlin, February 2024